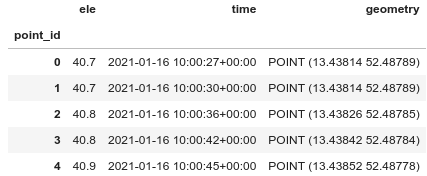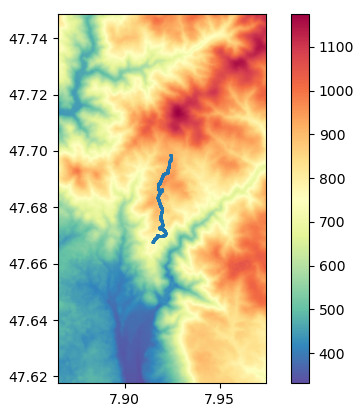
In Teil 1 dieser Serie habe ich einen einzelnen GPS-Track mit Geopandas und Folium untersucht. Der nächste Schritt besteht darin, den Code, der den GeoDataFrame vorbereitet, in eine Funktion zu verschieben. Dann lese ich alle GPX-Dateien eines bestimmten Ordners ein und übergebe jeden GPS-Track an meine Funktion.
Funktion zur Vorbereitung des GeoDataFrames
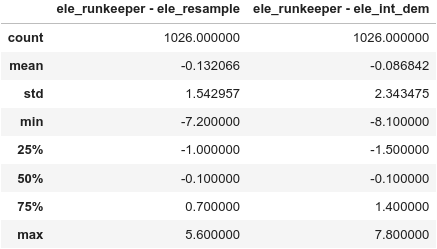
Nachdem ich einige Module importiert und den Ordner mit den GPX-Dateien festgelegt habe, definiere ich eine Funktion, die ziemlich genau dasselbe tut wie Teil 1. Ich habe Code hinzugefügt, um seltsame Ausreißer zu behandeln: Nach Pausen/Stopps (z. B. beim Warten an einer Ampel) war das von Runkeeper verwendete GPS manchmal etwas verwirrt und wusste nicht wirklich, wo ich war. In einem Fall war der erste Punkt nach einem Stopp 1,6 km von der tatsächlichen Position entfernt, was zu einem Liniensegment mit einer Geschwindigkeit von mehr als 400 km/h führte – und zu einer Gesamtstrecke, die um 3,3 km zu lang war.
import pandas as pd
import geopandas as gpd
import numpy as np
import os
from shapely.geometry import LineString
import folium
folder = "gpx/"
def prepare_dataframes(gdf, track_name):
""" Calculate distance, speed etc. from raw data of gpx trackpoints.
Return two GeoDataframes: points and (connecting) lines.
"""
gdf.index.names = ['point_id']
gdf['time'] = pd.to_datetime(gdf['time'])
gdf.dropna(axis=1, inplace=True)
gdf.drop(columns=['track_fid', 'track_seg_id', 'track_seg_point_id'], inplace=True)
# Use local UTM to get geometry in meters
gdf = gdf.to_crs(gdf.estimate_utm_crs())
# shifted gdf gives us the next point with the same index
# allows calculations without the need of a loop
shifted_gdf = gdf.shift(-1)
gdf['time_delta'] = shifted_gdf['time'] - gdf['time']
gdf['time_delta_s'] = gdf['time_delta'].dt.seconds
gdf['dist_delta'] = gdf.distance(shifted_gdf)
# In one track, after making a pause, I had a weird outlier 1.6 km away of my real position.
# Therefore I replace dist_delta > 100 m with NAN.
# This should be counted as pause.
gdf['dist_delta'] = np.where(gdf['dist_delta']>100, np.nan, gdf['dist_delta'])
# speed in various formats
gdf['m_per_s'] = gdf['dist_delta'] / gdf.time_delta.dt.seconds
gdf['km_per_h'] = gdf['m_per_s'] * 3.6
gdf['min_per_km'] = 60 / (gdf['km_per_h'])
# We now might have speeds with NAN (pauses, see above)
# Fill NAN with 0 for easy filtering of pauses
gdf['km_per_h'].fillna(0)
# covered distance (meters) and time passed
gdf['distance'] = gdf['dist_delta'].cumsum()
gdf['time_passed'] = gdf['time_delta'].cumsum()
# Minutes instead datetime might be useful
gdf['minutes'] = gdf['time_passed'].dt.seconds / 60
# Splits (in km) might be usefull for grouping
gdf['splits'] = gdf['distance'] // 1000
# ascent is = elevation delta, but only positive values
gdf['ele_delta'] = shifted_gdf['ele'] - gdf['ele']
gdf['ascent'] = gdf['ele_delta']
gdf.loc[gdf.ascent < 0, ['ascent']] = 0
# Slope in %
gdf['slope'] = 100 * gdf['ele_delta'] / gdf['dist_delta']
# slope and min_per_km can be infinite if 0 km/h
# Replace inf with nan for better plotting
gdf.replace(np.inf, np.nan, inplace=True)
gdf.replace(-np.inf, np.nan, inplace=True)
# Ele normalized: Startpoint as 0
gdf['ele_normalized'] = gdf['ele'] - gdf.loc[0]['ele']
# Back to WGS84 (we might have tracks from different places)
gdf = gdf.to_crs(epsg = 4326)
shifted_gdf = shifted_gdf.to_crs(epsg = 4326)
# Create another geodataframe with lines instead of points as geometry.
lines = gdf.iloc[:-1].copy() # Drop the last row
lines['next_point'] = shifted_gdf['geometry']
lines['line_segment'] = lines.apply(lambda row:
LineString([row['geometry'], row['next_point']]), axis=1)
lines.set_geometry('line_segment', inplace=True, drop=True)
lines.drop(columns='next_point', inplace=True)
lines.index.names = ['segment_id']
# Add track name and use it for multiindex
gdf['track_name'] = track_name
lines['track_name'] = track_name
gdf.reset_index(inplace=True)
gdf.set_index(['track_name', 'point_id'], inplace=True)
lines.reset_index(inplace=True)
lines.set_index(['track_name', 'segment_id'], inplace=True)
return gdf, lines
Jetzt können wir die GPX-Dateien öffnen und unsere GeoDataFrames mit Daten befüllen.
# Prepare empty Geodataframes
points = gpd.GeoDataFrame()
lines = gpd.GeoDataFrame()
# And populate them with data from gpx files
for file in os.listdir(folder):
if file.endswith(('.gpx')):
try:
rawdata = gpd.read_file(folder + file, layer='track_points')
track_points, track_lines = prepare_dataframes(rawdata, file)
points = pd.concat([points, track_points])
lines = pd.concat([lines, track_lines])
except:
print("Error", file)
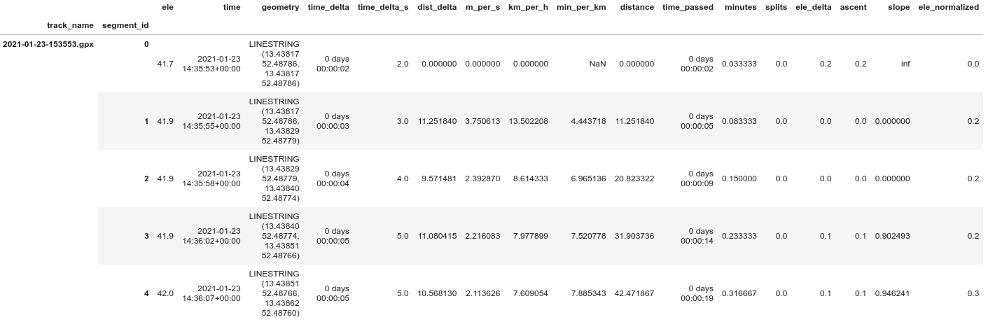
lines.head()
Sind die Liniensegmente vergleichbar?
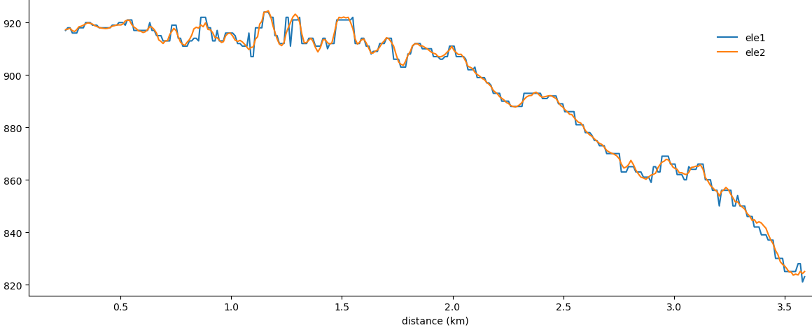
Einfache Diagramme wären aussagekräftiger, wenn jedes Liniensegment eine ähnliche Länge in Bezug auf Zeit oder Entfernung hätte. Meine Schlussfolgerung nach der Untersuchung verschiedener Diagramme von 'dist_delta', 'time_delta' und Geschwindigkeit: Die Frequenz der Messungen ist normalerweise ein Punkt alle 3 bis 6 Sekunden. Runkeeper scheint die Frequenz entsprechend der aktuellen Geschwindigkeit zu ändern und erhält ziemlich regelmäßige Abstände zwischen den Messpunkten (ein Punkt alle 9 bis 12 m). Die Ausnahme sind Abschnitte mit sehr niedrigen Geschwindigkeiten von 0 bis 1,5 km/h, d. h. Pausen. Ich denke, dies macht die Liniensegmente vergleichbar genug, um sie für einfache Diagramme zu verwenden. Wir können davon ausgehen, dass jedes Segment etwa 10 m lang ist oder eine Pause darstellt. Wir könnten darüber nachdenken, Segmente mit sehr niedrigen Geschwindigkeiten herauszufiltern.
Manchmal hatte ich absurd hohe Geschwindigkeiten, wenn das GPS-Signal nicht genau war. Dies geschah unter Brücken oder direkt nach einer Pause/einem Stopp. Auch diese können wir herausfiltern.
Einfache Statistik
Mit ein paar Zeilen Code können wir einige grundlegende Statistiken über unsere Spuren erhalten. Versuchen Sie das Folgende:
Anstieg in Metern:
lines.groupby('track_name')['ascent'].sum()
Auch interessant:
lines.groupby('track_name')['ascent'].sum().describe()
Distanz in Metern:
lines.groupby('track_name')['distance'].sum().describe()
Geschwindigkeit:
lines.groupby('track_name')['km_per_h'].describe()
Nützliche Informationen über jeden Lauf extrahieren
Ich erstelle einen Pandas-Dataframe mit allgemeinen Informationen über jeden Lauf, wie Entfernung, Steigung, Durchschnittsgeschwindigkeit. Ich berechne auch die Zeit der Pausen (alle Intervalle mit sehr niedriger Geschwindigkeit, ich setze den Schwellenwert auf 1,5 km/h).
runs = pd.DataFrame({
'distance': lines.groupby('track_name')['dist_delta'].sum(),
'ascent': lines.groupby('track_name')['ascent'].sum(),
'start_time': points.groupby('track_name')['time'].min(),
'end_time': points.groupby('track_name')['time'].max(),
'median_km_h' : lines.groupby('track_name')['km_per_h'].median()
})
runs['total_duration'] = runs['end_time'] - runs['start_time']
# Pauses (speed <1.5 km/h)
runs['pause'] = lines[
lines['km_per_h']<1.5
].groupby('track_name')['time_delta'].sum()
runs['pause'] = runs['pause'].fillna(pd.Timedelta(0))
# Duration without pauses
runs['duration'] = runs['total_duration'] - runs['pause']
runs['minutes'] = runs.duration.dt.seconds / 60
# Speed
runs['m_per_s'] = runs['distance'] / runs.duration.dt.seconds
runs['km_per_h'] = runs['m_per_s'] * 3.6
runs['min_per_km'] = 60 / runs['km_per_h']
# Distance in km
runs['distance'] = runs['distance'] / 1000
Wir können runs auch in einen GeoDataFrame umwandeln und die Geometrie der gesamten Strecke hinzufügen:
# Add Geometry of the (complete) runs
runs = gpd.GeoDataFrame(runs, geometry=lines.dissolve(by='track_name')['geometry'])
Für eine einfache Statistik:
runs.describe()
Einfache Abfragen
Sie wollen vermutlich den schnellsten oder längsten Lauf oder ähnliche Informationen suchen.
Die 5 längsten Läufe:
runs.sort_values(by='distance', ascending=False).head(5)
Die 5 schnellsten Läufe:
runs.sort_values(by='km_per_h', ascending=False).head(5)
Die schnellsten Läufe mit einer Länge zwischen 8 und 12 km:
runs[(runs['distance']>=8) & (runs['distance']<=12)].sort_values(by='km_per_h', ascending=False).head(5)
Berichte über Monate und Jahre
Wie viele Aktivitäten hatte ich letztes Jahr? Welche Strecke habe ich im März insgesamt zurückgelegt? Wir können eine Tabelle erstellen, um solche Fragen zu beantworten.
Bericht pro Jahr:
per_year = pd.DataFrame({
'count': runs.groupby(runs.start_time.dt.year)['distance'].count(),
'total_distance': runs.groupby(runs.start_time.dt.year)['distance'].sum(),
'distance_median': runs.groupby(runs.start_time.dt.year)['distance'].median(),
'distance_mean': runs.groupby(runs.start_time.dt.year)['distance'].mean(),
'distance_max': runs.groupby(runs.start_time.dt.year)['distance'].max(),
'total_ascent': runs.groupby(runs.start_time.dt.year)['ascent'].sum(),
'ascent_median': runs.groupby(runs.start_time.dt.year)['ascent'].sum(),
'ascent_max': runs.groupby(runs.start_time.dt.year)['ascent'].max(),
'median_km_h' : runs.groupby(runs.start_time.dt.year)['km_per_h'].median(),
'mean_km_h' : runs.groupby(runs.start_time.dt.year)['km_per_h'].mean(),
})
per_year.index.name = 'year'
per_year
Bericht pro Monate:
per_month = pd.DataFrame({
'count': runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['distance'].count(),
'total_distance': runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['distance'].sum(),
'distance_median': runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['distance'].median(),
'distance_mean': runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['distance'].mean(),
'distance_max': runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['distance'].max(),
'total_ascent': runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['ascent'].sum(),
'ascent_median': runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['ascent'].sum(),
'ascent_max': runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['ascent'].max(),
'median_km_h' : runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['km_per_h'].median(),
'mean_km_h' : runs.groupby([runs.start_time.dt.year,
runs.start_time.dt.month])['km_per_h'].mean(),
})
per_month.index.names = ['year', 'month']
per_month
Die folgende Alternative zeigt auch Monate ohne Aktivität an (nützlich zum Plotten):
freq = runs.set_index('start_time').groupby(pd.Grouper(freq="M"))
freq_month = pd.DataFrame({
'count': freq['distance'].count(),
'total_distance': freq['distance'].sum(),
'distance_median': freq['distance'].median(),
'distance_mean': freq['distance'].mean(),
'distance_max': freq['distance'].max(),
'total_ascent': freq['ascent'].sum(),
'ascent_median': freq['ascent'].sum(),
'ascent_max': freq['ascent'].max(),
'median_km_h' : freq['km_per_h'].median(),
'mean_km_h' : freq['km_per_h'].mean(),
})
freq_month.index.name = 'month_dt'
freq_month['year'] = freq_month.index.year
freq_month['month'] = freq_month.index.month
freq_month
Plot: freq_month['count'].plot(kind='bar')
Plots mit Seaborn
Nun können Sie Ihre Kenntnisse der Datenvisualisierung ausleben. In diesem Beitrag zeige ich nur einige Beispiele, viele weitere finden Sie im Jupyter-Notebook.
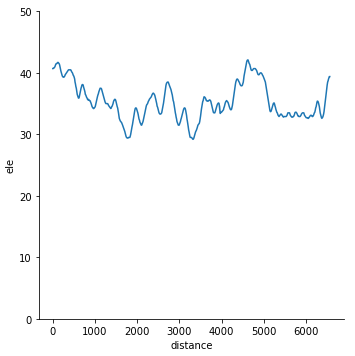
Profile der GPS-Tracks:
sns.relplot(x="distance", y="ele", data=lines, kind="line", hue="track_name");
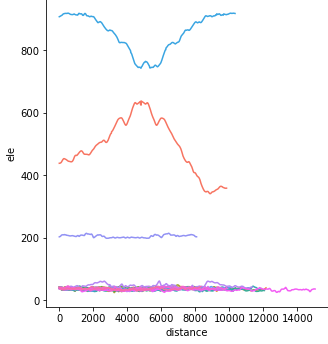
Sie können auch eine normalisierte Version ausprobieren, bei der alle Tracks bei Null beginnen:
sns.relplot(x="distance", y="ele_normalized", data=lines, kind="line", hue="track_name");
Hängt die Geschwindigkeit mit der Steigung zusammen? (Beachten Sie, dass ich unrealistisch hohe Geschwindigkeiten herausfiltere)
sns.relplot(x="slope", y="km_per_h", data=lines[lines['km_per_h']<30], hue="track_name");
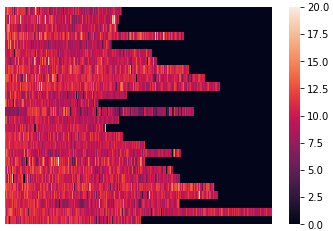
Eine heatmap der Geschwindigkeit:
heatmapdata1 = lines.reset_index()
heatmapdata1 = heatmapdata1.pivot(index='track_name', columns='segment_id', values='km_per_h')
heatmapdata1.fillna(value=0, inplace=True)
# Set vmax to filter out unrealistic values
sns.heatmap(heatmapdata1, vmin=0, vmax=20, xticklabels=False)
Eine Heatmap von ele_delta ist ebenfalls interessant. Ich setze Minimal- und Maximalwerte, ansonsten wäre das Ergebnis fast komplett schwarz.
heatmapdata2 = lines.reset_index()
heatmapdata2 = heatmapdata2.pivot(index='track_name', columns='segment_id', values='ele_delta')
heatmapdata2.fillna(value=0, inplace=True)
sns.heatmap(heatmapdata2, xticklabels=False, center=0, vmin=-2, vmax=2)
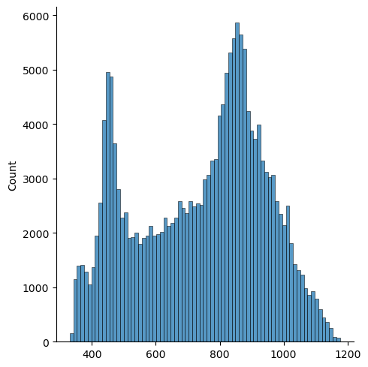
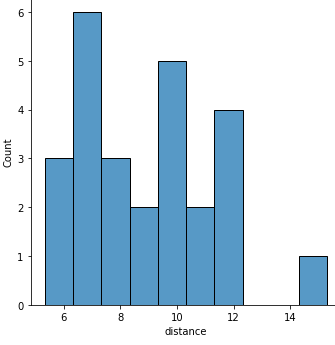
Ein Histogramm der Länge der Läufe:
sns.displot(x="distance", data=runs, binwidth=1);
Versuchen Sie auch Geschwindigkeit vs. Länge
sns.relplot(x="distance", y="km_per_h", data=runs, hue="track_name")
Geschwindigkeit (und Länge) vs. Datum:
import matplotlib.dates as mdates
g = sns.relplot(x="start_time", y="km_per_h", data=runs, size="distance", sizes=(2,300))
g.ax.set_xlabel("date")
g.ax.set_ylabel("km/h")
g.ax.xaxis.set_major_formatter(
mdates.ConciseDateFormatter(g.ax.xaxis.get_major_locator()))
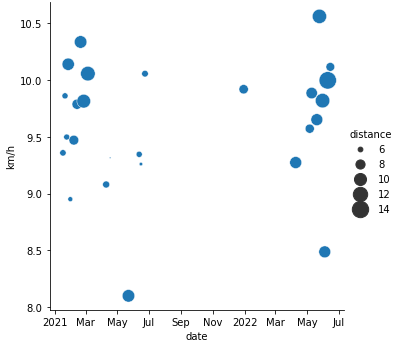
und:
g = sns.relplot(x="start_time", y="distance", data=runs, size="km_per_h")
g.ax.set_xlabel("date")
g.ax.set_ylabel("distance")
g.ax.xaxis.set_major_formatter(
mdates.ConciseDateFormatter(g.ax.xaxis.get_major_locator()))
Länge vs. Minuten:
sns.jointplot(x="distance", y="minutes", data=runs, kind="reg")
Wir können auch die Monatsberichte plotten. Für schönere Diagramme ersetze ich Jahr und Monat durch einen Datetime-Index.
per_month_dt = per_month.reset_index()
per_month_dt['month'] = pd.to_datetime(per_month_dt['year'].astype('str') + '-' + per_month_dt['month'].astype('str') + '-1')
per_month_dt.drop(columns='year', inplace=True)
per_month_dt.set_index('month', inplace=True)
Und jetzt können Sie die monatliche Gesamtstrecke zeichnen:
g = sns.relplot(x="month", y="total_distance", data=per_month_dt)
g.ax.xaxis.set_major_formatter(
mdates.ConciseDateFormatter(g.ax.xaxis.get_major_locator()))
Oder den Median der Geschwindigkeit für jeden Monat:
g = sns.relplot(x="month", y="median_km_h", data=per_month_dt)
g.ax.xaxis.set_major_formatter(
mdates.ConciseDateFormatter(g.ax.xaxis.get_major_locator()))
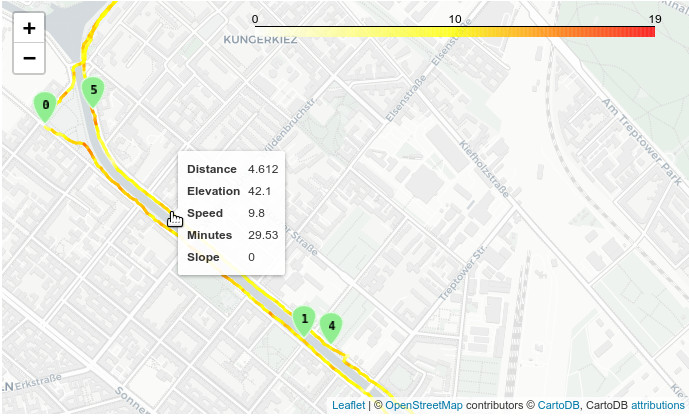
Interaktive Karte mit Folium
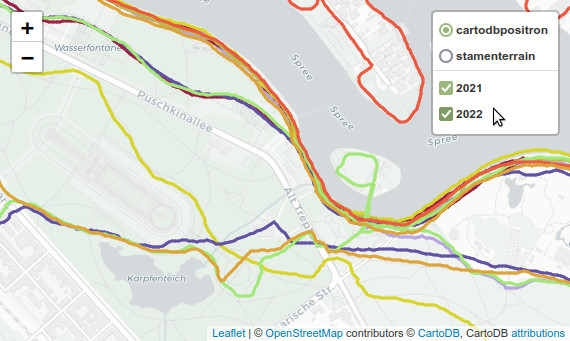
Schließlich können wir Folium verwenden, um alle GPS-Tracks auf einer interaktiven Karte darzustellen (siehe Screenshot am Anfang meines Beitrags). Die Karte hat Tooltips, die die tatsächliche Geschwindigkeit, Kilometerzahl, Zeit usw. jedes Streckenabschnitts anzeigen. Die Läufe eines jeden Jahres können ein- und ausgeschaltet werden, und man kann eine von zwei verschiedenen Basiskarten wählen.
Für aussagekräftige Tooltips muss ich die tatsächlichen Streckenabschnitte (lines) anstelle der kompletten Läufe (runs) verwenden. Zuerst erstelle ich einen bereinigten GeoDataFrame ohne Datetime (sonst versagt Folium) und mit gerundeten Werten (für schönere Tooltips).
lines_condensed = lines[['ele_delta', 'dist_delta', 'geometry', 'distance', 'km_per_h', 'min_per_km', 'minutes', 'slope', 'time_delta_s']].dropna().copy()
lines_condensed['date'] = lines['time'].dt.strftime("%d %B %Y")
lines_condensed['year'] = lines['time'].dt.year
lines_condensed['month'] = lines['time'].dt.month
lines_condensed.reset_index(level=1, inplace=True)
lines_condensed['total_distance'] = runs['distance']
lines_condensed['total_minutes'] = runs['minutes']
lines_condensed['distance'] = lines_condensed['distance']/1000
lines_condensed['distance'] = lines_condensed['distance'].round(2)
lines_condensed['total_distance'] = lines_condensed['total_distance'].round(2)
lines_condensed['total_minutes'] = lines_condensed['total_minutes'].round(2)
lines_condensed['minutes'] = lines_condensed['minutes'].round(2)
lines_condensed['min_per_km'] = lines_condensed['min_per_km'].round(2)
lines_condensed['km_per_h'] = lines_condensed['km_per_h'].round(2)
lines_condensed['slope'] = lines_condensed['slope'].round(3)
Wir brauchen eine Style-Funktion, und ich weise jedem Lauf eine zufällige Farbe zu.
# style function
def style(feature):
return {
# 'fillColor': feature['properties']['color'],
'color': feature['properties']['color'],
'weight': 3,
}
for x in lines_condensed.index:
color = np.random.randint(16, 256, size=3)
color = [str(hex(i))[2:] for i in color]
color = '#'+''.join(color).upper()
lines_condensed.at[x, 'color'] = color
Ich verwende den letzten (jüngsten) Standort als Zentrum der Karte.
location_x = lines_condensed.iloc[-1]['geometry'].coords.xy[0][0]
location_y = lines_condensed.iloc[-1]['geometry'].coords.xy[1][0]
Grupieren nach Jahr:
grouped = lines_condensed.groupby('year')
Endlich können wir die Karte plotten. (Die FeatureGroups habe ich her erklärt.)
m = folium.Map(location=[location_y, location_x], zoom_start=13, tiles='cartodbpositron')
folium.TileLayer('Stamen Terrain').add_to(m)
# Iterate through the grouped dataframe
# Populate a list of feature groups
# Add the tracks to the feature groups
# And add the feature groups to the map
f_groups = []
for group_name, group_data in grouped:
f_groups.append(folium.FeatureGroup(group_name))
track_geojson = folium.GeoJson(data=group_data, style_function=style).add_to(f_groups[-1])
track_geojson.add_child(
folium.features.GeoJsonTooltip(fields=['date', 'distance', 'total_distance', 'minutes', 'total_minutes', 'min_per_km', 'km_per_h' ],
aliases=['Date', 'Kilometers', 'Total km', 'Minutes', 'Total min', 'min/km', 'km/h'])
)
f_groups[-1].add_to(m)
folium.LayerControl().add_to(m)
m
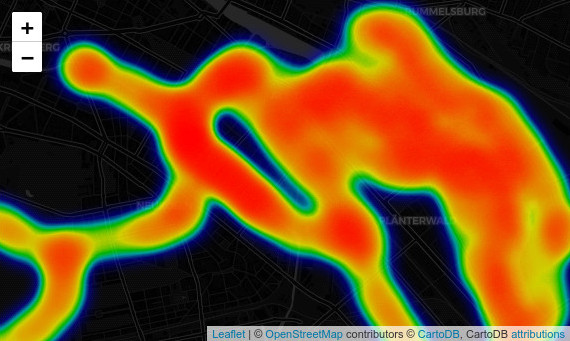
Heatmap mit Folium
Folium kann auch eine interaktive Heatmap plotten. Das Plugin heatmap benötigt eine Liste von Orten, die wir aus unserem GeoDataFrame mit den Punkten erhalten können. Es lohnt sich, mit den Parametern zu spielen, vor allem radius und blur.
# Create a list of the locations from points
locations = list(zip(points['geometry'].y, points['geometry'].x))
hm = folium.Map(tiles='cartodbdark_matter')
# Add heatmap to map instance
# Available parameters: HeatMap(data, name=None, min_opacity=0.5, max_zoom=18, max_val=1.0, radius=25, blur=15, gradient=None, overlay=True, control=True, show=True)
folium.plugins.HeatMap(locations).add_to(hm)
hm